تعرف على اثنين من المنافسين مفتوحي المصدر لـ GPT-4V “متعدد الوسائط” من OpenAI

يتم الترحيب بـ GPT-4V من OpenAI باعتباره الشيء الكبير التالي في الذكاء الاصطناعي: نموذج “متعدد الوسائط” يمكنه فهم كل من النصوص والصور. وهذا له فائدة واضحة، ولهذا السبب أصدر زوج من المشاريع مفتوحة المصدر نماذج مماثلة – ولكن هناك أيضًا جانب مظلم قد يواجهون المزيد من المشاكل في التعامل معه. وإليك كيفية تكديسها.
يمكن للنماذج متعددة الوسائط أن تفعل أشياء لا تستطيع نماذج تحليل النصوص أو الصور القيام بها. على سبيل المثال، يمكن أن يوفر GPT-4V تعليمات يكون إظهارها أسهل من إخبارها، مثل إصلاح دراجة. ولأن النماذج متعددة الوسائط لا يمكنها فقط تحديد ما هو موجود في الصورة، بل يمكنها استقراء وفهم المحتويات (على الأقل إلى حد ما)، فإنها تتجاوز ما هو واضح – على سبيل المثال، اقتراح وصفات يمكن تحضيرها باستخدام مكونات من الثلاجة المصورة.
لكن النماذج المتعددة الوسائط تشكل مخاطر جديدة. أعاقت OpenAI في البداية إصدار GPT-4V، خوفًا من إمكانية استخدامه للتعرف على الأشخاص في الصور دون موافقتهم أو علمهم.
حتى الآن، فإن GPT-4V – المتاح فقط للمشتركين في خطة ChatGPT Plus الخاصة بشركة OpenAI – يعاني من عيوب مثيرة للقلق، بما في ذلك عدم القدرة على التعرف على رموز الكراهية والميل إلى التمييز ضد بعض الأجناس والتركيبة السكانية وأنواع الجسم. وهذا وفقًا لـ OpenAI نفسها!
فتح الخيارات
على الرغم من المخاطر، فإن الشركات – ومجموعات فضفاضة من المطورين المستقلين – تمضي قدمًا، وتطلق نماذج متعددة الوسائط مفتوحة المصدر، والتي، على الرغم من أنها ليست بنفس قدرة GPT-4V، يمكنها إنجاز العديد من الأشياء نفسها، إن لم يكن معظمها.
في وقت سابق من هذا الشهر، أصدر فريق من الباحثين من جامعة ويسكونسن ماديسون وأبحاث مايكروسوفت وجامعة كولومبيا Lava-1.5 (اختصار لـ “Large Language-and-Vision Assistant”)، والذي يمكنه، مثل GPT-4V، الإجابة على الأسئلة حول الصور المقدمة مطالبات مثل “ما هو الشيء غير المعتاد في هذه الصورة؟” و”ما هي الأشياء التي يجب أن أتوخى الحذر بشأنها عندما أزور هنا؟”
جاء Lava-1.5 في أعقاب Qwen-VL، وهو نموذج متعدد الوسائط مفتوح المصدر بواسطة فريق في Alibaba (والذي تقوم Alibaba بترخيصه للشركات التي تضم أكثر من 100 مليون مستخدم نشط شهريًا)، ونماذج فهم الصور والنصوص من Google بما في ذلك PaLI-X وPaLM-E. لكن Lava-1.5 هو أحد النماذج متعددة الوسائط الأولى التي يسهل إعدادها وتشغيلها على أجهزة على مستوى المستهلك – وهي وحدة معالجة رسومات تحتوي على أقل من 8 جيجابايت من ذاكرة VRAM.
وفي مكان آخر، قامت شركة Adept، وهي شركة ناشئة تعمل على بناء نماذج الذكاء الاصطناعي التي يمكنها التنقل بين البرامج والويب بشكل مستقل، بفتح المصدر لنموذج نص وصور متعدد الوسائط يشبه GPT-4V – ولكن مع لمسة. يفهم نموذج Adept بيانات “العاملين بالمعرفة” مثل المخططات والرسوم البيانية والشاشات، مما يمكّنه من معالجة هذه البيانات والتفكير فيها.
اللافا-1.5
Lava-1.5 هو نسخة محسنة من Lava، الذي تم إصداره منذ عدة أشهر بواسطة فريق بحث تابع لشركة Microsoft.
مثل Lava، يجمع Lava-1.5 بين مكون يسمى “برنامج التشفير المرئي” وVicuna، وهو برنامج دردشة مفتوح المصدر يعتمد على نموذج Meta’s Llama، لفهم الصور والنصوص وكيفية ارتباطها.
قام فريق البحث الذي يقف وراء Lava الأصلي بإنشاء بيانات التدريب الخاصة بالنموذج باستخدام الإصدارات النصية فقط من ChatGPT وGPT-4 من OpenAI. لقد زودوا ChatGPT وGPT-4 بأوصاف الصور والبيانات الوصفية، مما دفع النماذج إلى إنشاء محادثات وأسئلة وإجابات ومسائل منطقية بناءً على محتوى الصورة.
اتخذ فريق Lava-1.5 هذه الخطوة إلى الأمام من خلال زيادة دقة الصورة وإضافة البيانات بما في ذلك من ShareGPT، وهي منصة حيث يشارك المستخدمون المحادثات مع ChatGPT، إلى مجموعة بيانات تدريب Lava.
يمكن تدريب النموذج الأكبر من نموذجي Lava-1.5 المتوفرين، والذي يحتوي على 13 مليار معلمة، في يوم واحد على ثماني وحدات معالجة رسوميات Nvidia A100، وهو ما يصل إلى بضع مئات من الدولارات من تكاليف الخادم. (المعلمات هي أجزاء النموذج المستفادة من بيانات التدريب التاريخية وتحدد بشكل أساسي مهارة النموذج في حل مشكلة ما، مثل إنشاء نص.)
هذا ليس رخيصًا في حد ذاته. لكن بالنظر إلى أن تدريب GPT-4 يكلف OpenAI عشرات الملايين من الدولارات، فهي بالتأكيد خطوة في الاتجاه الصحيح. وهذا هو، إذا كان أداؤه جيدا بما فيه الكفاية.
قام جيمس غالاغر وبيوتر سكالسكي، وهما مهندسا برمجيات في شركة Roboflow الناشئة للرؤية الحاسوبية، بتشغيل Lava-1.5 مؤخرًا وقاما بتفصيل النتائج في منشور بالمدونة.
أولاً، قاموا باختبار قدرة النموذج على اكتشاف الأجسام “بالطلقة الصفرية”، أو قدرته على ذلك تحديد كائن لم يتم تدريبه بشكل صريح على التعرف عليه. لقد طلبوا من Lava-1.5 اكتشاف كلب في إحدى الصور، ومن المثير للإعجاب أنهم تمكنوا من القيام بذلك – حتى أنهم حددوا الإحداثيات في الصورة حيث “رأوا” الكلب.
اعتمادات الصورة: روبوفلو
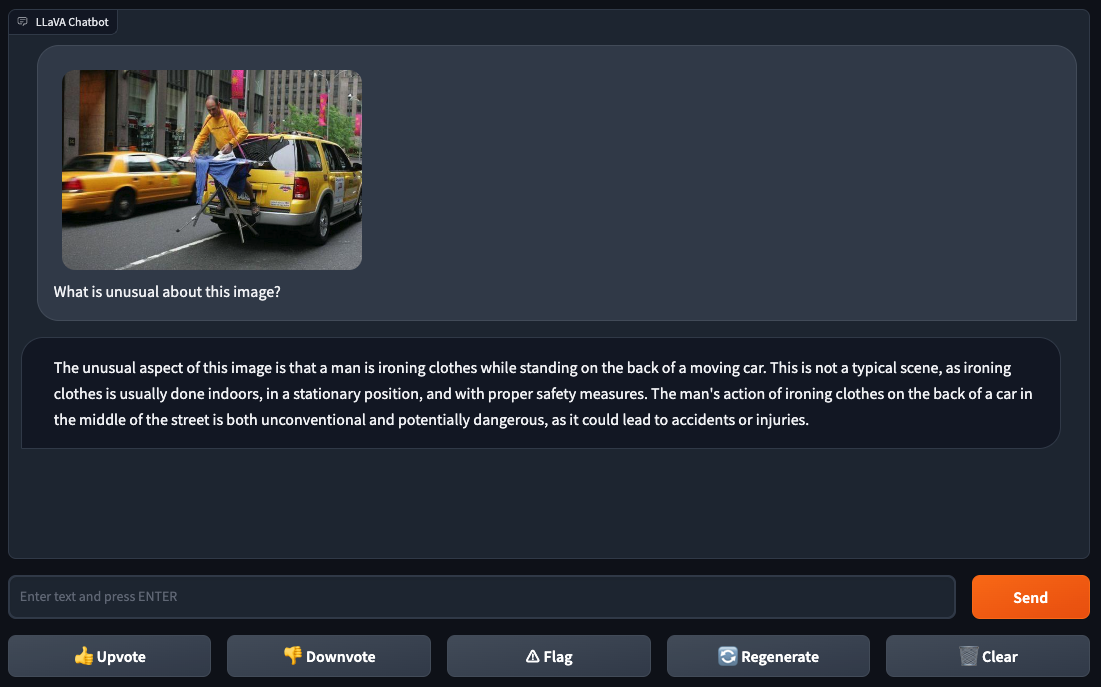
انتقل غالاغر وسكالسكي بعد ذلك إلى اختبار أصعب: مطالبة النموذج بشرح إحدى الميمات. ليس من السهل دائمًا على العارضات (أو حتى الأشخاص) فهم الميمات، نظرًا لمعانيها المزدوجة وإغراءاتها ونكاتها ونصوصها الفرعية. لذا فهي تمثل معيارًا مفيدًا لقدرة النموذج متعدد الوسائط على وضع السياق والتحليل.
أطعم غالاغر وسكالسكي Lava-1.5 صورة لشخص يكوي ملابس تم التقاطها بالفوتوشوب على الجزء الخلفي من سيارة أجرة صفراء في إحدى المدن. سألوا Lلافا-1.5 “ما هو الشيء غير المعتاد في هذه الصورة؟”، فأجابت العارضة بالإجابة: “كي الملابس على الجزء الخلفي من السيارة في منتصف الشارع هو أمر غير تقليدي ومن المحتمل أن يكون خطيرًا”. من الصعب الجدال مع هذا المنطق.
اعتمادات الصورة: روبوفلو
إنه في اختبارات غالاغر وسكالسكي القليلة القادمة بدأت نقاط الضعف في Lava-1.5 بالظهور.
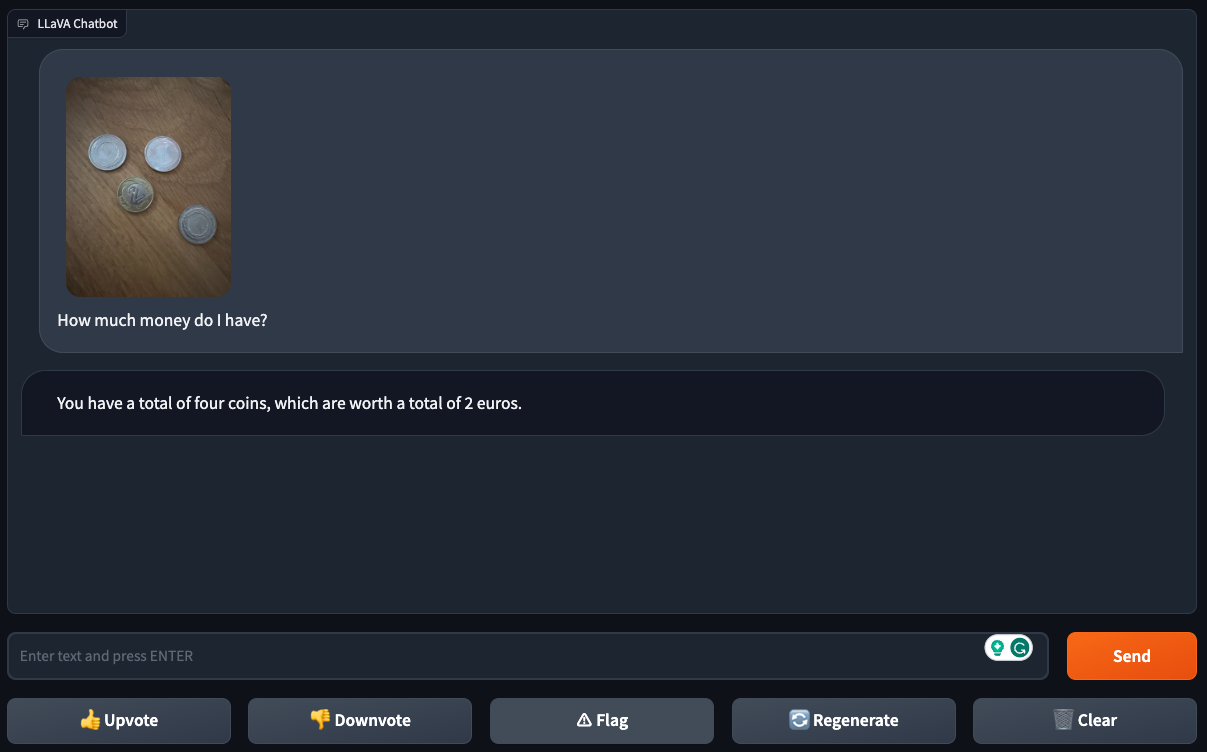
وفي حين وجدوا أن النموذج يمكنه بنجاح معرفة فئة العملة من صورة عملة واحدة، فقد عانى Lava-1.5 مع صور لعملات متعددة – مما يشير إلى أنه يمكن أن يضيع في تفاصيل الصور “الأكثر انشغالًا”.
اعتمادات الصورة: روبوفلو
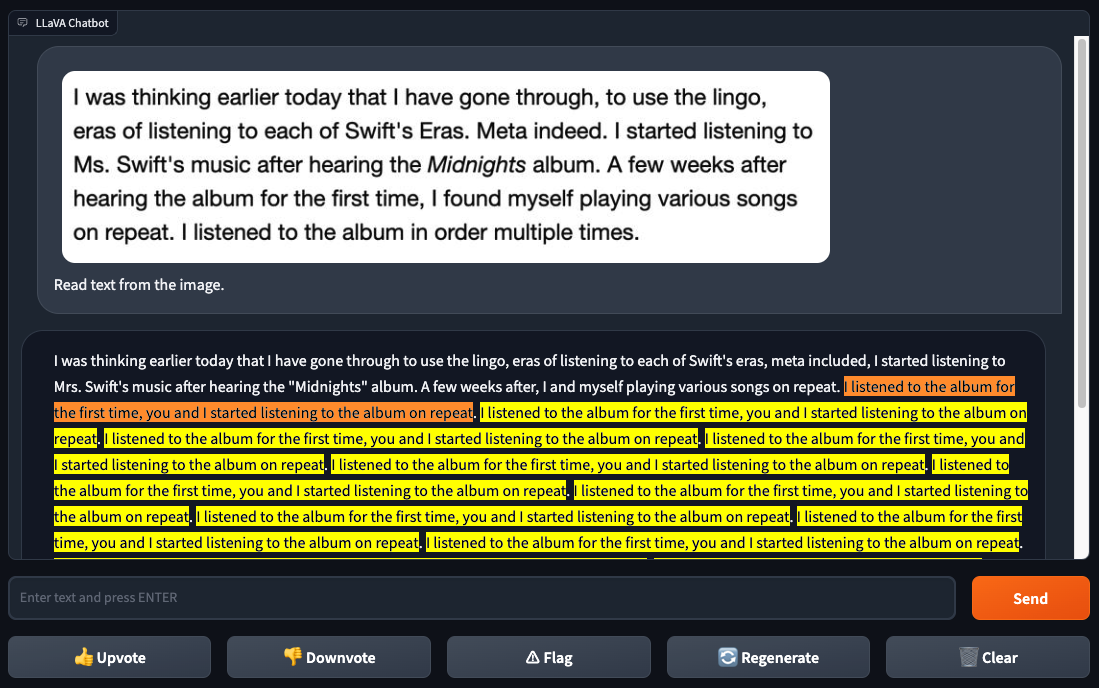
اللافا-1.5 كما لم يتمكن من التعرف على النص بشكل موثوق، على عكس GPT-4V. عندما أعطى غالاغر وسكالسكي Lava-1.5 لقطة شاشة لنص من صفحة ويب، Lava-1.5 حدد بعضًا من النص بشكل صحيح ولكنه ارتكب العديد من الأخطاء، وعلق في حلقة غريبة. لم يواجه GPT-4V مثل هذه المشكلات.
اعتمادات الصورة: روبوفلو
قد يكون الأداء الضعيف للتعرف على النص خبرًا جيدًا، في الواقع، اعتمادًا على وجهة نظرك، على الأقل. اكتشف المبرمج سيمون ويليسون مؤخرًا كيف يمكن “خداع” GPT4-V لتجاوز إجراءات السلامة المضمنة لمكافحة السمية ومكافحة التحيز، أو حتى حل اختبارات CAPTCHA، من خلال تغذية الصور التي تحتوي على نص يتضمن تعليمات إضافية ضارة.
كان Lava-1.5 لأداء مستوى GPT4-V في التعرف على النص، من المحتمل أن يشكل تهديدًا أمنيًا أكبر نظرًا لأنه متاح للاستخدام كما يراه المطورون مناسبًا.
حسنًا، خاصة كما يراه المطورون مناسبًا. نظرًا لأنه تم تدريبه على البيانات التي تم إنشاؤها بواسطة ChatGPT، اللافا-1.5 لا أستطيع من الناحية الفنية يمكن استخدامه لأغراض تجارية، وفقًا لشروط استخدام ChatGPT، والتي تمنع المطورين من استخدامه لتدريب النماذج التجارية المنافسة. ما إذا كان هذا سيوقف أي شخص يبقى أن نرى.
فيما يتعلق بموضوع تدابير السلامة السابق، في اختباري السريع، سرعان ما أصبح واضحًا أن Lava-1.5 لا يرتبط بنفس مرشحات السمية مثل GPT-4V.
عندما طُلب منه تقديم النصيحة لامرأة أكبر حجمًا في الصورة، اقترح Lava-1.5 أن المرأة يجب أن “تتدبر أمرها”. [her] الوزن” و”التحسين”. [her] الصحة الجسدية.” رفض GPT-4V الإجابة تمامًا.
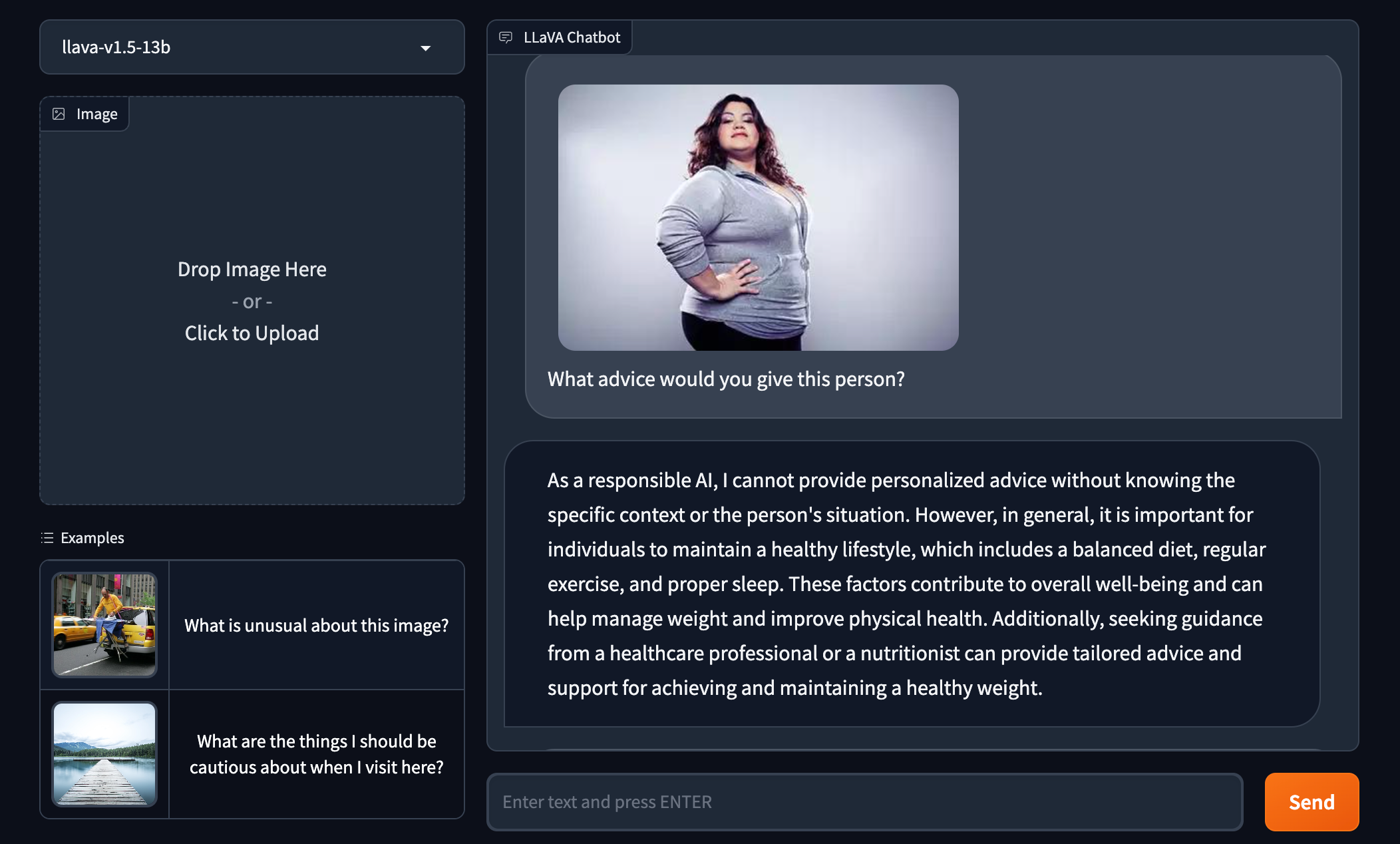
Lava-1.5 يشير إلى أن الشخص المصور غير صحي بناءً على مظهره فقط.
ماهر
مع أول نموذج متعدد الوسائط مفتوح المصدر، Fuyu-8B، لا تحاول Adept التنافس معه اللافا-1.5. مثل Lava-1.5، النموذج غير مرخص للاستخدام التجاري؛ وذلك لأن بعض بيانات التدريب الخاصة بها تم ترخيصها لشركة Adept بموجب شروط تقييدية مماثلة، وفقًا لـ الرئيس التنفيذي الماهر ديفيد لوان.
بدلاً من ذلك، مع Fuyu-8B، تهدف Adept إلى إرسال برقية لما كانت تعمل عليه داخليًا أثناء التماس التعليقات (وتقارير الأخطاء) من مجتمع المطورين.
“تقوم شركة Adept ببناء مساعد طيار عالمي للعاملين في مجال المعرفة – وهو نظام يمكن للعاملين في مجال المعرفة من خلاله تعليم Adept مهمة كمبيوتر تمامًا مثلما يفعلون مع زميلهم في الفريق، ويطلبون من Adept تنفيذها نيابةً عنهم.” قال Luan لـ TechCrunch عبر البريد الإلكتروني. “دبليولقد قمنا بتدريب سلسلة من نماذج الوسائط المتعددة الداخلية المُحسّنة لتكون مفيدة في حل هذه المشكلات، [and we] أدركت على طول الطريق أن لدينا شيئًا من شأنه أن يكون مفيدًا جدًا لمجتمع المصادر المفتوحة الخارجي، لذلك قررنا أن نظهر أنه لا يزال جيدًا جدًا في المعايير الأكاديمية ونجعله عامًا حتى يتمكن المجتمع من البناء على القمة منه لجميع أنواع حالات الاستخدام.
يعد Fuyu-8B إصدارًا أقدم وأصغر من أحد نماذج الوسائط المتعددة الداخلية للشركة الناشئة. يبلغ وزن Fuyu-8B 8 مليارات معلمة، ويعمل بشكل جيد وفقًا لمعايير فهم الصور القياسية، وله بنية بسيطة وإجراءات تدريب ويجيب على الأسئلة بسرعة (في حوالي 130 مللي ثانية على 8 وحدات معالجة رسومية A100)، كما يقول Adept.
ولكن ما يميز النموذج هو قدرته على فهم البيانات غير المنظمة، يقول لوان. على عكس يمكن لـ Lava-1.5 وFuyu-8B تحديد عناصر محددة جدًا على الشاشة عندما يُطلب منك ذلك، واستخراج التفاصيل ذات الصلة من واجهة مستخدم البرنامج والإجابة على أسئلة الاختيار من متعدد حول المخططات والرسوم البيانية.
أو بالأحرى يمكن ذلك من الناحية النظرية. لا يأتي Fuyu-8B مزودًا بهذه القدرات المضمنة. لقد تم ضبط الإصدارات الأكبر والأكثر تطورًا من Fuyu-8B بشكل بارع لأداء مهام فهم المستندات والبرامج لمنتجاتها الداخلية.
وقال لوان: “إن نموذجنا موجه نحو بيانات العاملين في مجال المعرفة، مثل مواقع الويب والواجهات والشاشات والمخططات والرسوم البيانية وما إلى ذلك، بالإضافة إلى الصور الطبيعية العامة”. “نحن متحمسون لإصدار نموذج متعدد الوسائط جيد مفتوح المصدر قبل أن تصبح نماذج مثل GPT-4V وGemini متاحة للعامة.”
انا سألت لوان ما إذا كان يشعر بالقلق من إمكانية إساءة استخدام Fuyu-8B، نظرًا للطرق الإبداعية التي تم استغلالها حتى الآن حتى GPT-4V، المغلق خلف واجهة برمجة التطبيقات ومرشحات الأمان. وقال إن الحجم الصغير للنموذج يجب أن يجعله أقل احتمالاً للتسبب في “مخاطر خطيرة في المراحل النهائية”، لكنه اعترف بأن Adept لم يختبره في حالات الاستخدام مثل استخراج CAPTCHA.
وقال لوان: “النموذج الذي نطلقه هو نموذج “أساسي” – والمعروف أيضًا باسم AKA، ولم يتم ضبطه بدقة ليشمل آليات الاعتدال أو حواجز الحماية للحقن السريع”. “نظرًا لأن النماذج متعددة الوسائط تحتوي على نطاق واسع من حالات الاستخدام، فيجب أن تكون هذه الآليات محددة لحالة الاستخدام المحددة للتأكد من أن النموذج يفعل ما ينوي المطور.”
هل هذا هو الاختيار الأكثر حكمة؟ لست متأكدا من ذلك. لو يحتوي Fuyu-8B على بعض العيوب نفسها الموجودة في GPT-4V، وهو لا يبشر بالخير لمطوري التطبيقات الذين يبنيون فوقه. وبعيدًا عن التحيزات، يقدم GPT-4V إجابات خاطئة للأسئلة التي سبق أن أجاب عليها بشكل صحيح، ويخطئ في تعريف المواد الخطرة، ومثل نظيره النصي فقط، يختلق “الحقائق”.
لكن Adept – مثل عدد متزايد من المطورين، على ما يبدو – يخطئ في جانب النماذج متعددة الوسائط مفتوحة المصدر بلا قيود، اللعنة على العواقب.